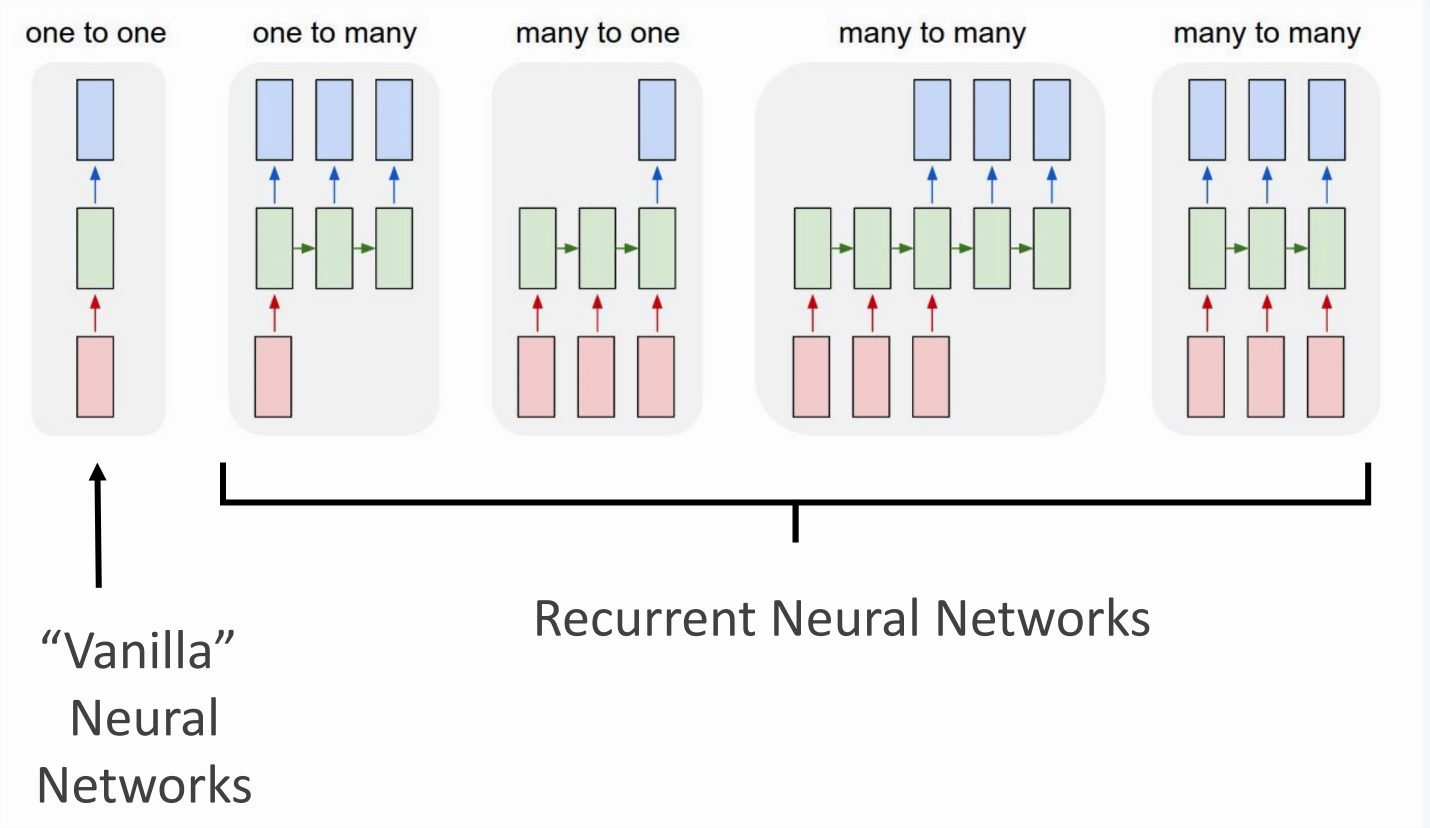
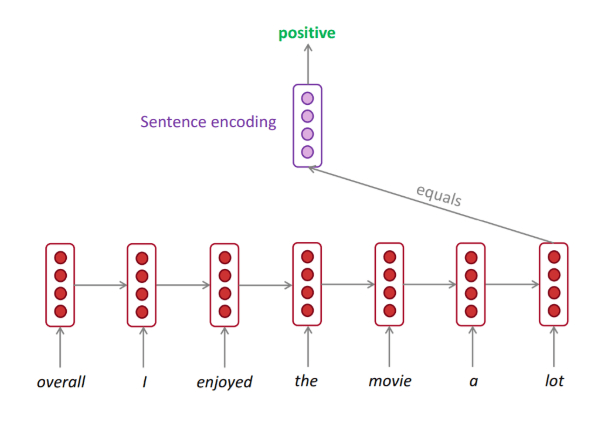
Unfolded RNN
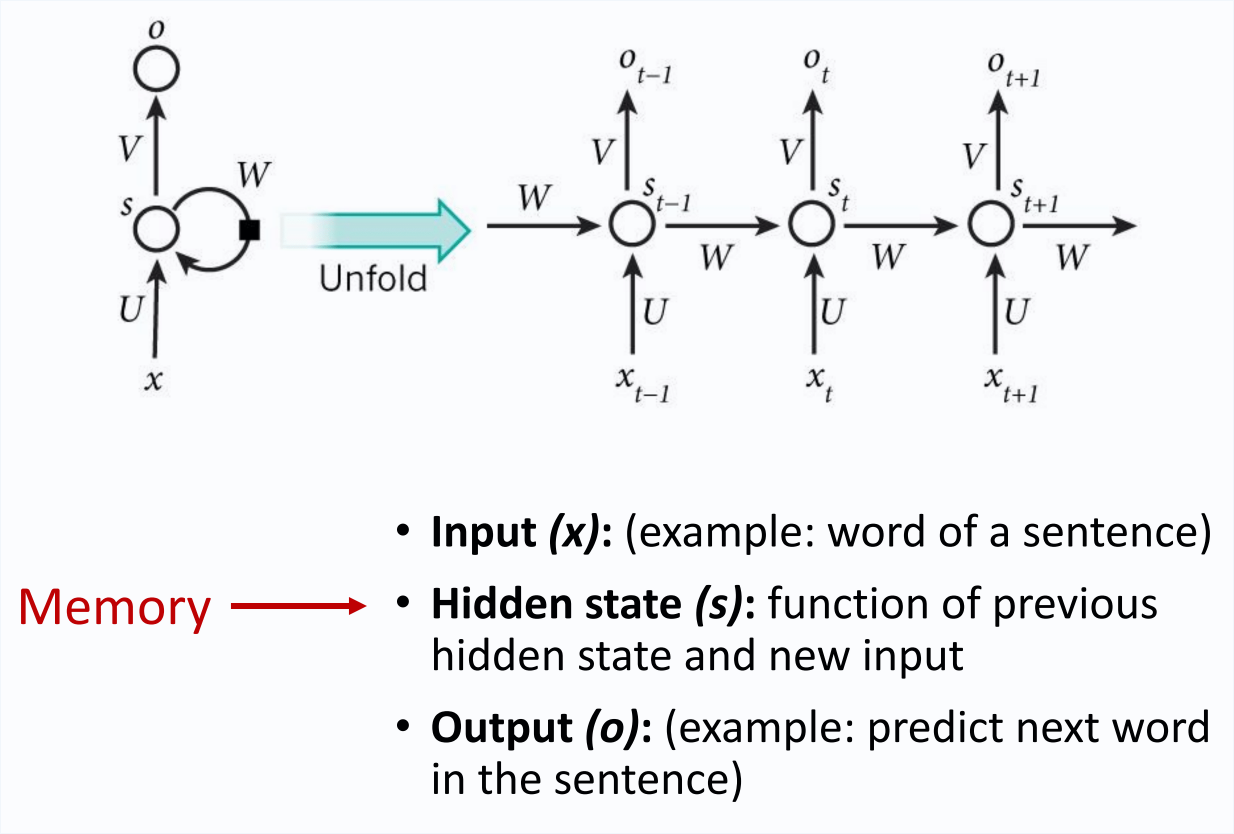
Unfolded RNN
Training unfolded RNN
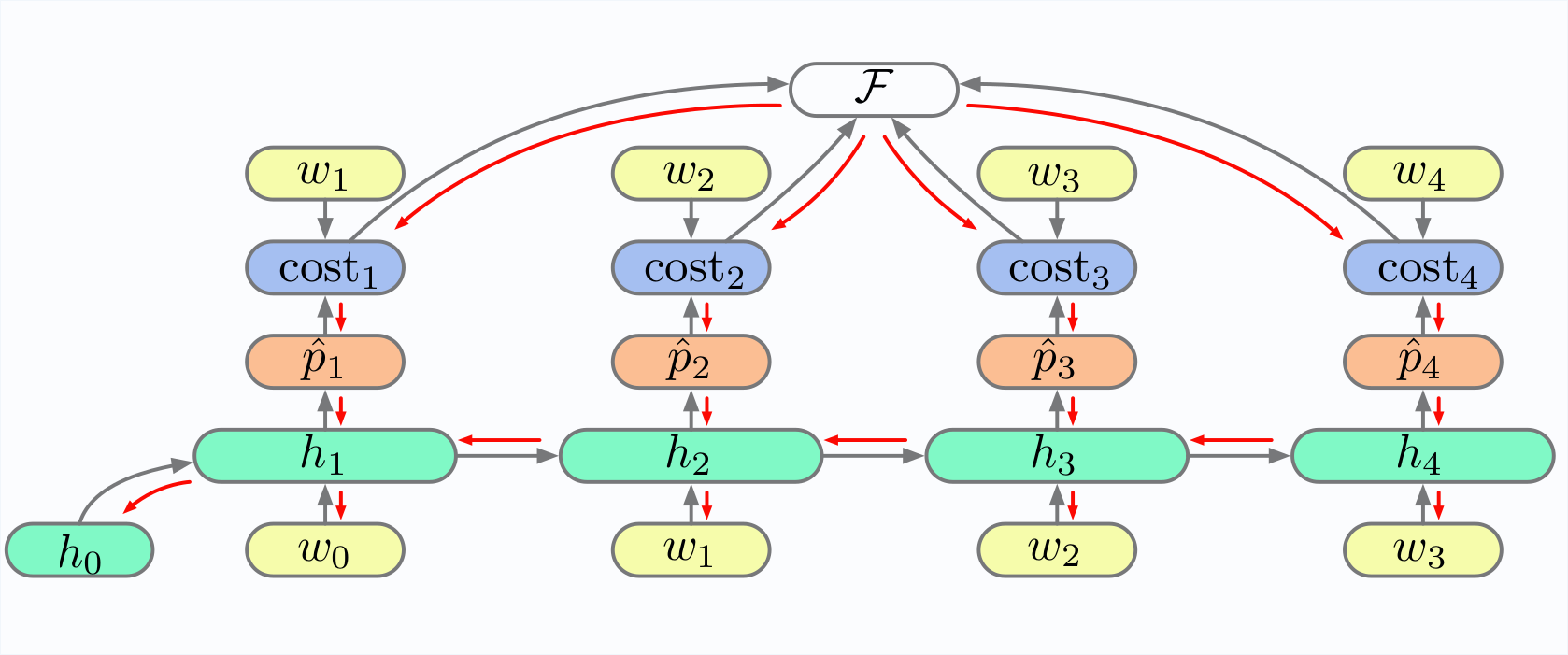
This concept is called Back Propagation Through Time (BPTT)
Training unfolded RNN
This concept is called Back Propagation Through Time (BPTT)
Training unfolded RNN
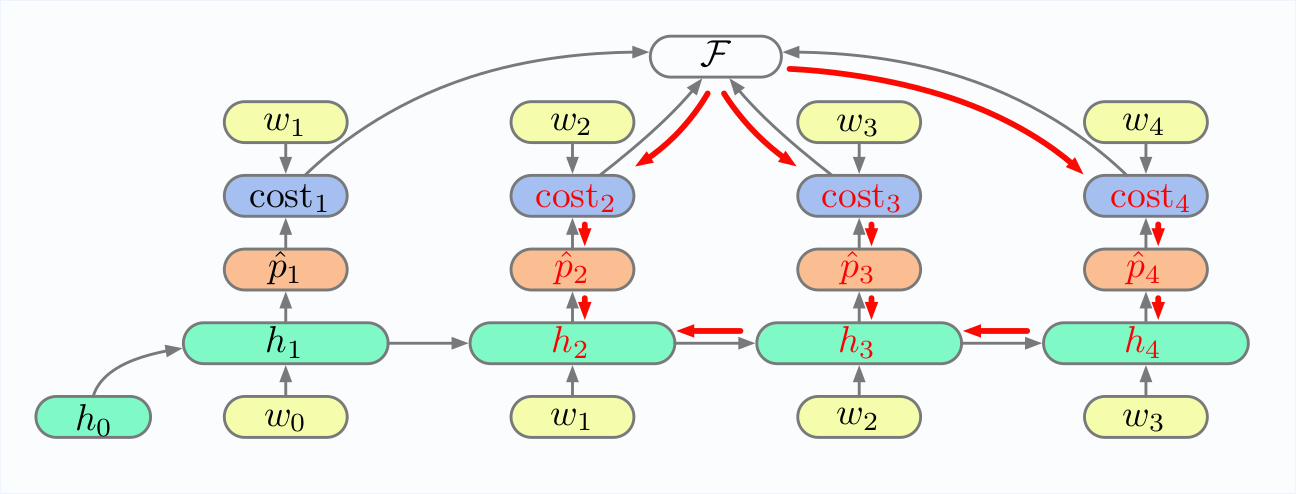
Note how various parts of the unfolded RNN impact h2
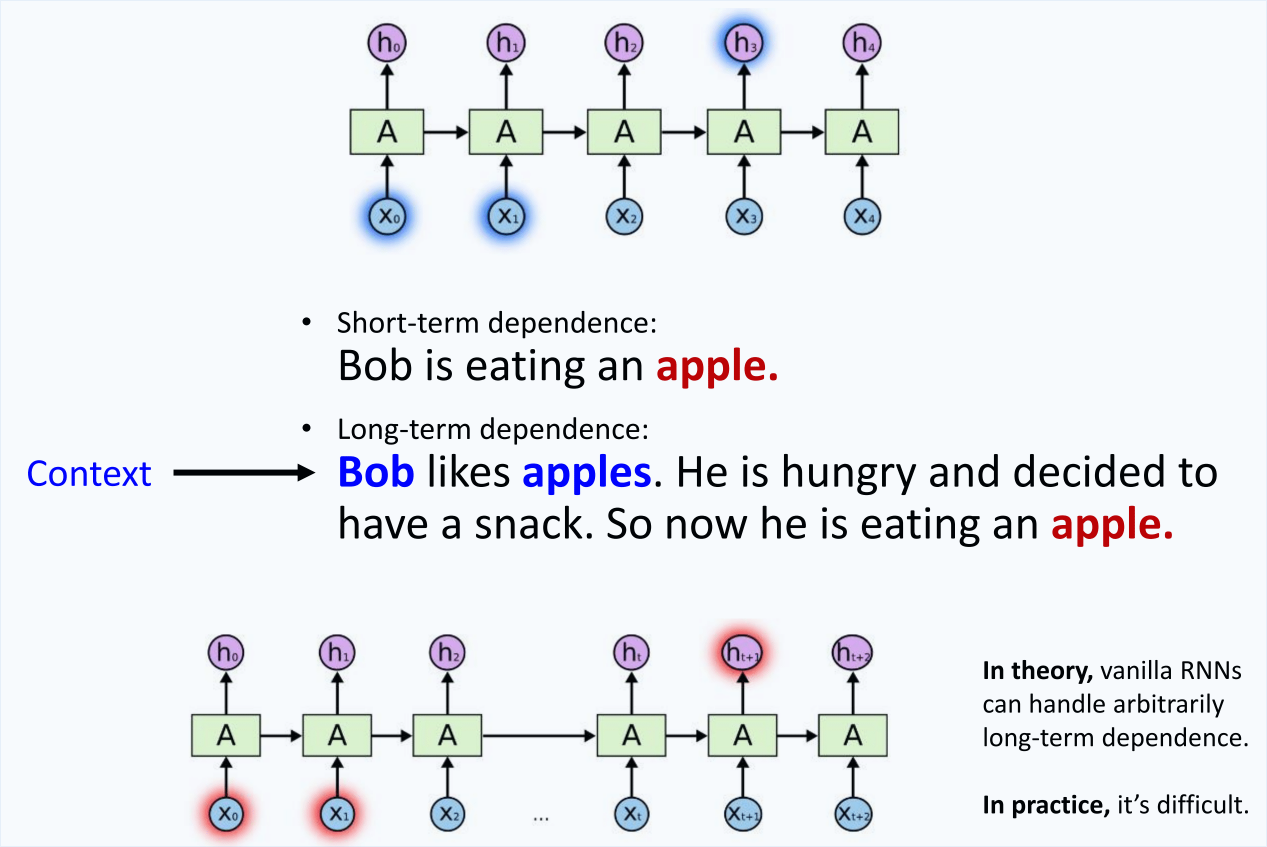
Problems with long-term dependencies
LSTM: what to forget and what to remember
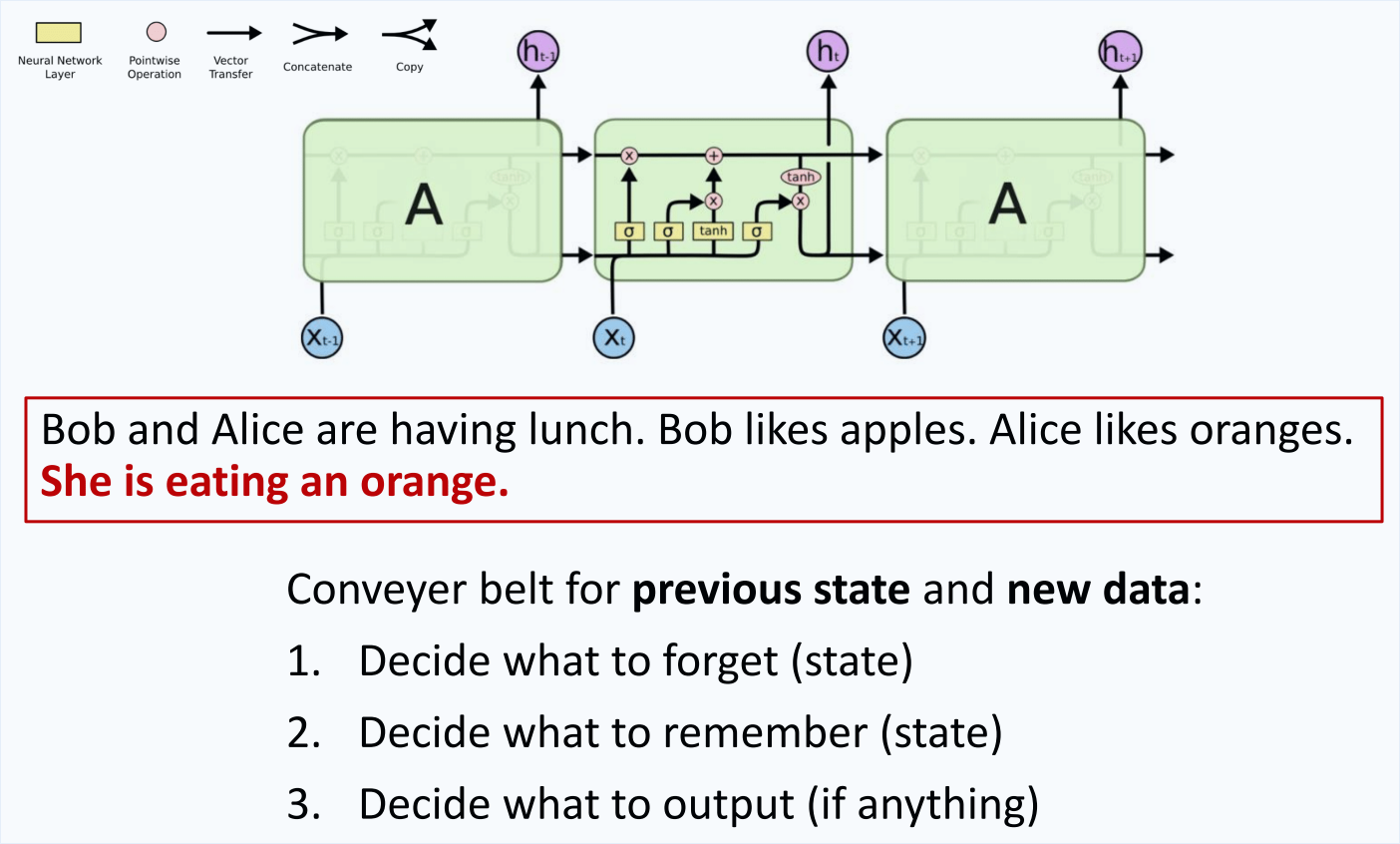
LSTM: Conveyor belt
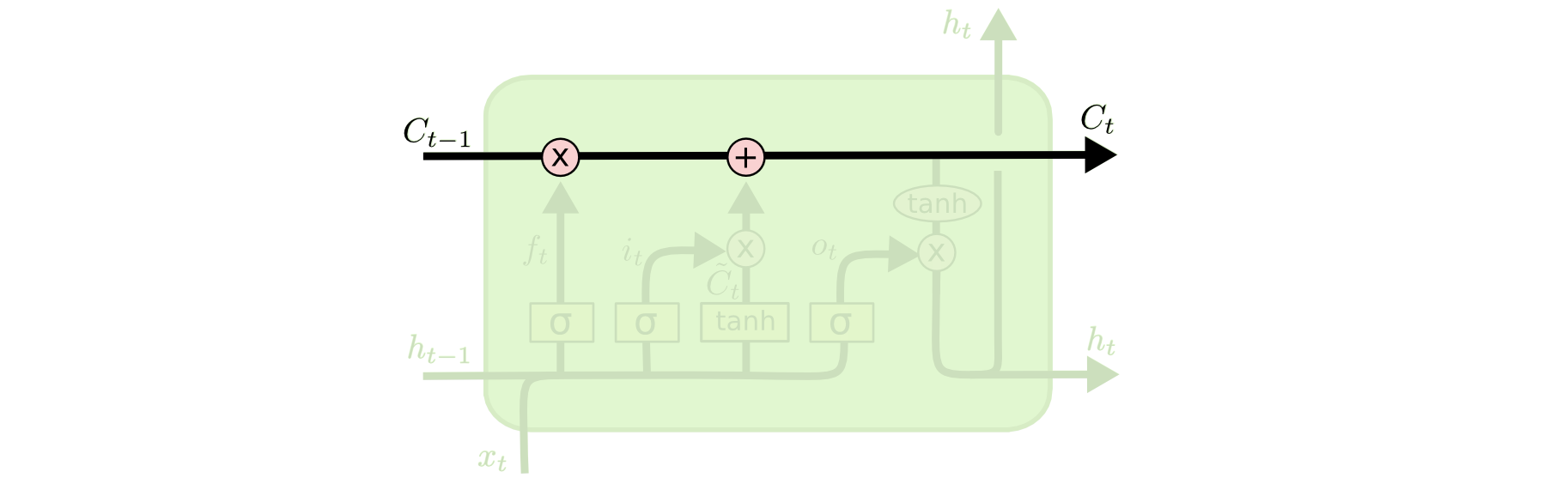
LSTM: Conveyor belt
- The cell state is sort of a "conveyor belt"
LSTM: Conveyor belt
The cell state is sort of a "conveyor belt"
Allows information to stay unchanged or get slightly updated
All the following nice images are from http://colah.github.io/posts/2015-08-Understanding-LSTMs/ which I highly recommend
LSTM: Conveyor belt
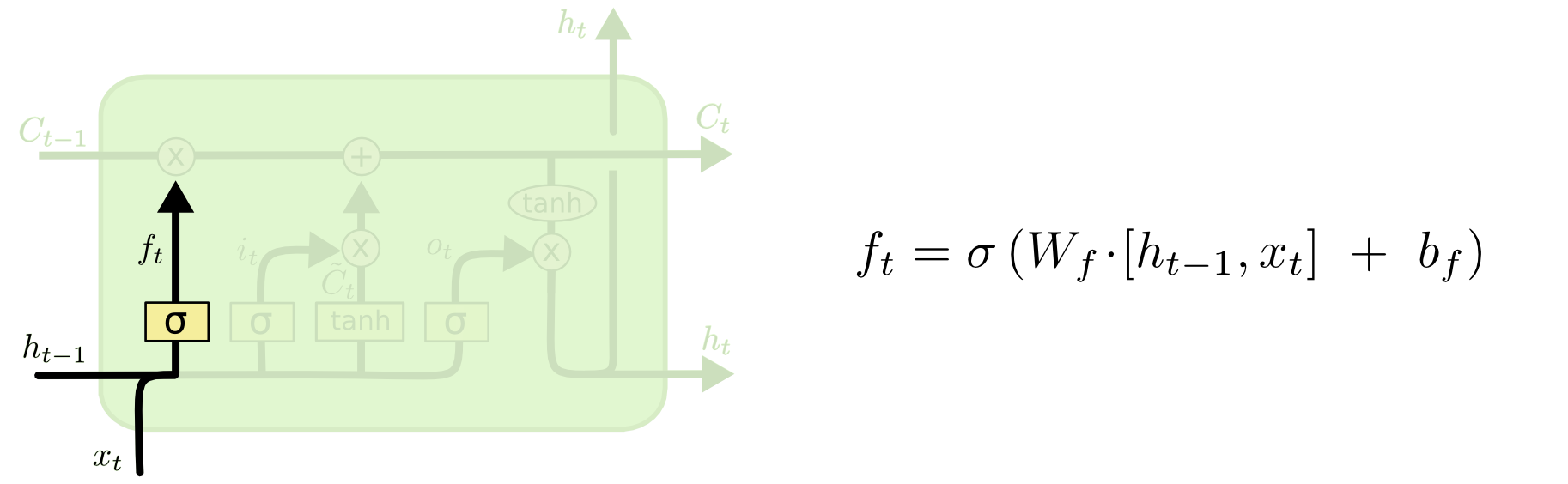
Step 1: Decide what to forget
LSTM: Conveyor belt
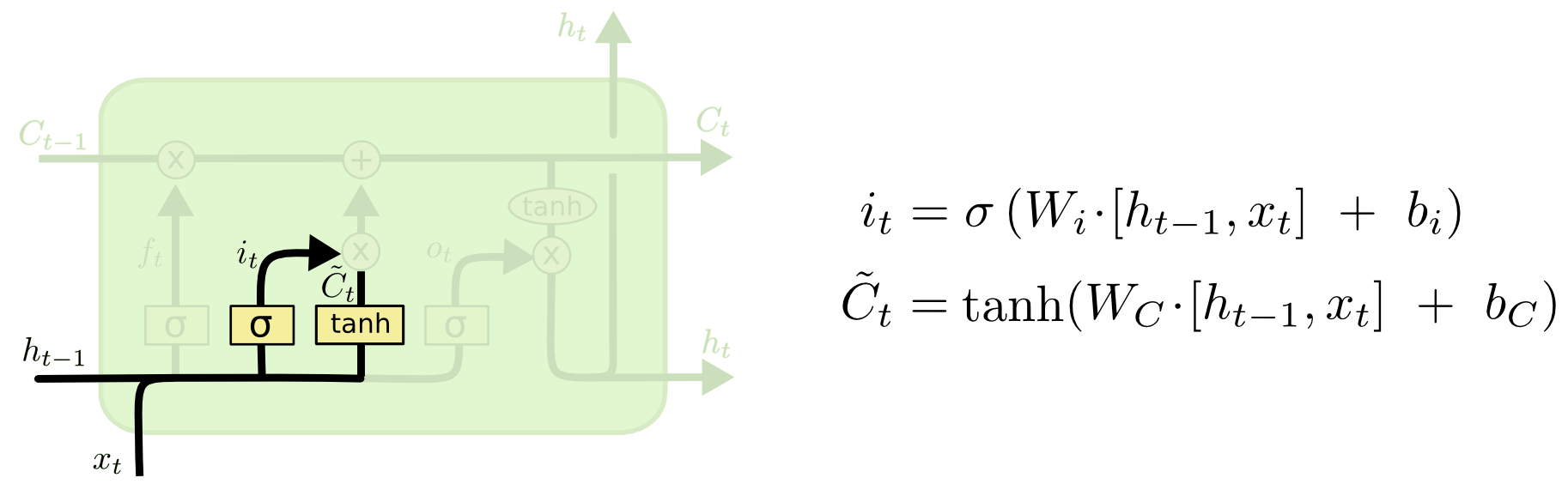
Step 2: Decide
- which values to update (it)
- what should the new values be (ˆCt)
LSTM: Conveyor belt
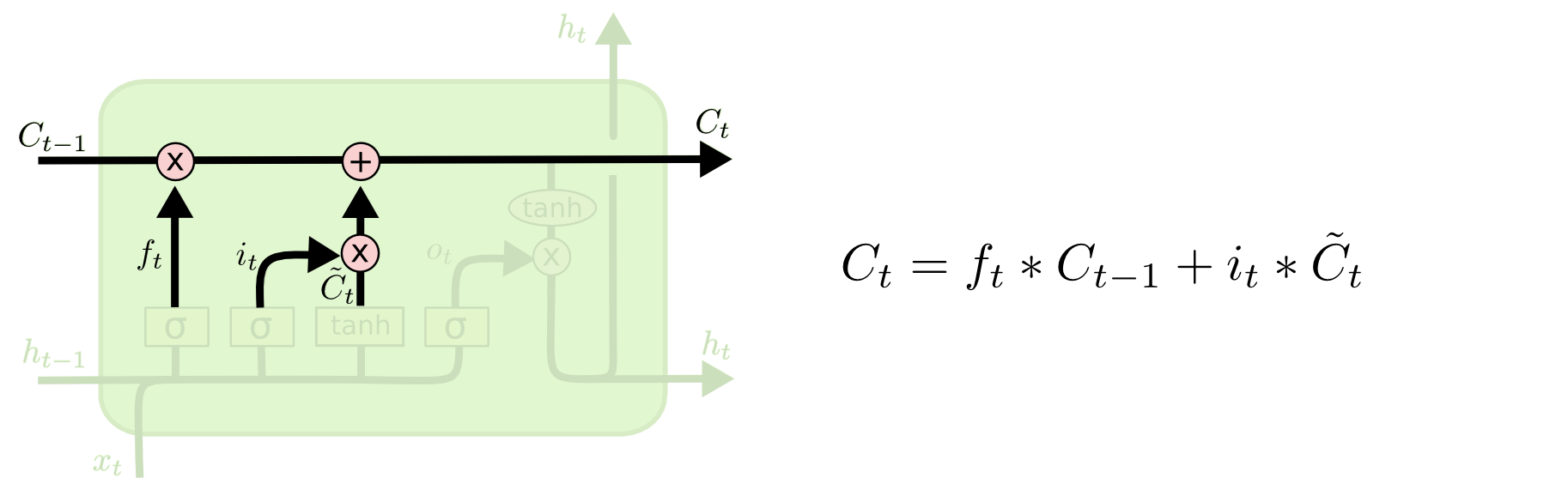
Step 2.5: perform forgetting and update
LSTM: Conveyor belt
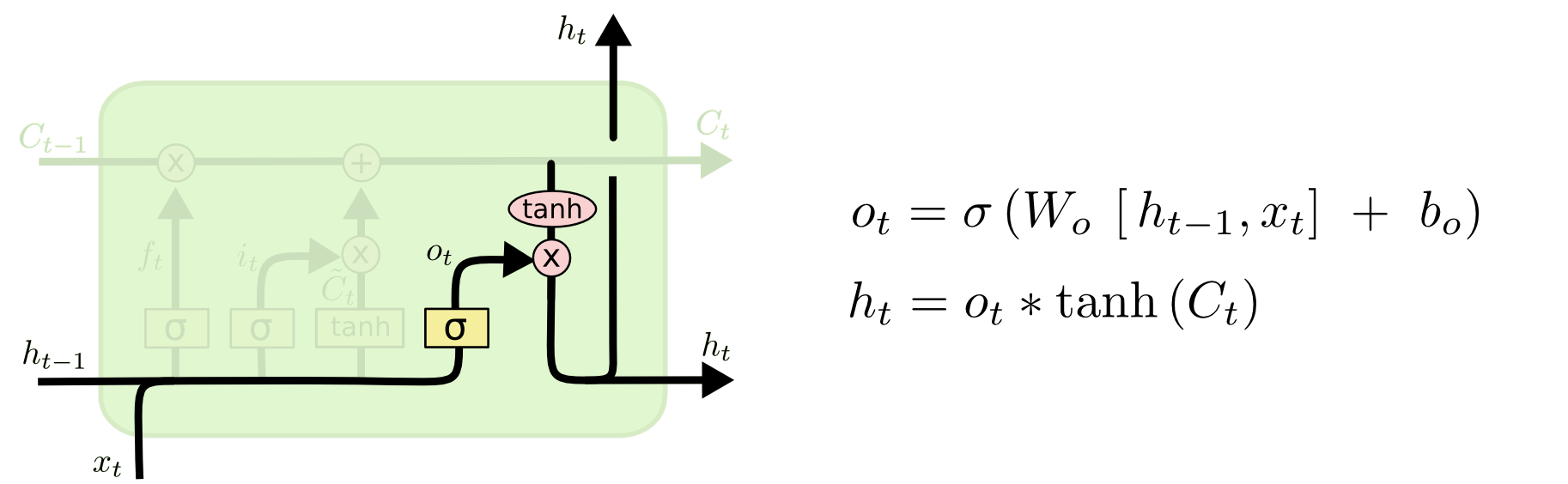
Step 3: produce output (ht)
LSTM: Conveyor belt
A coveyor belt that can pick
- what to remember
- what to forget
- what to output
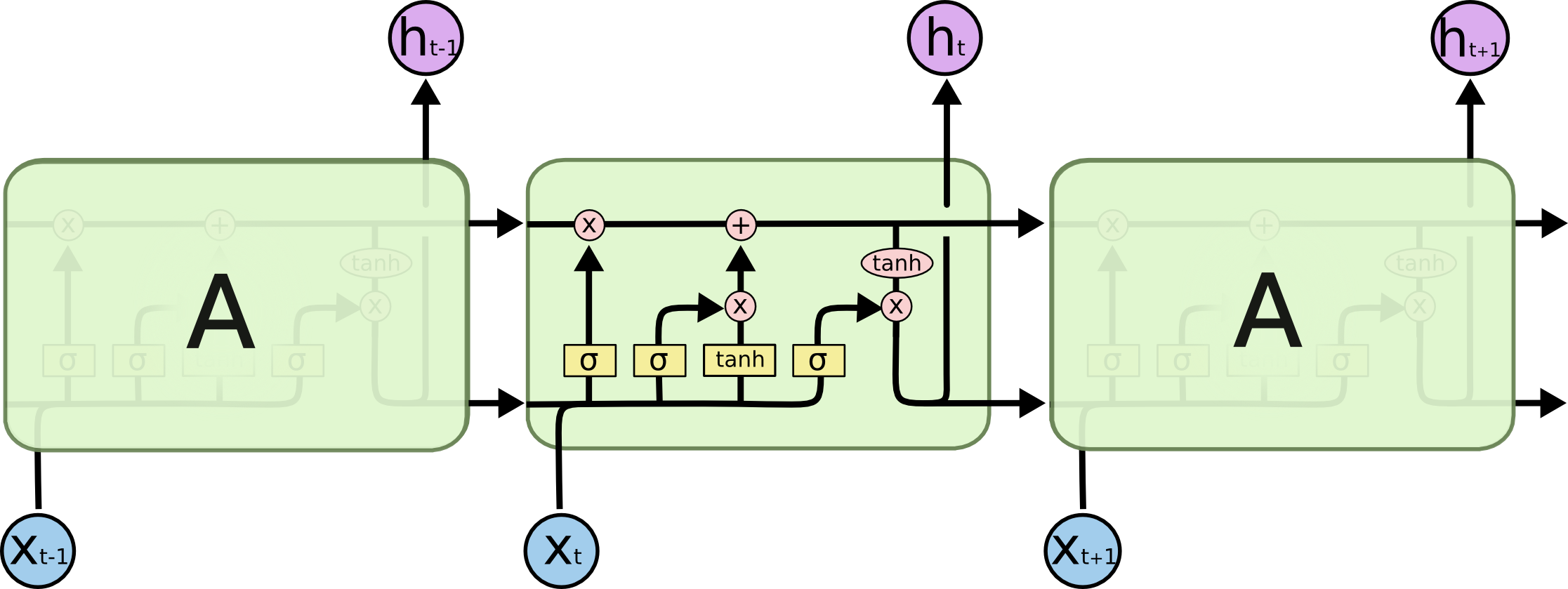
GRU: Simplified conveyor belt

GRU: Simplified conveyor belt
- Forget and input combined into a single "update gate" (zt)
GRU: Simplified conveyor belt
Forget and input combined into a single "update gate" (zt)
Cell state (Ct in LSTM) merged with the hidden state (ht)
GRU vs LSTM
- GRU is smaller and hence requires less compute
- But it turns out it cannot count (especially longer sequences)
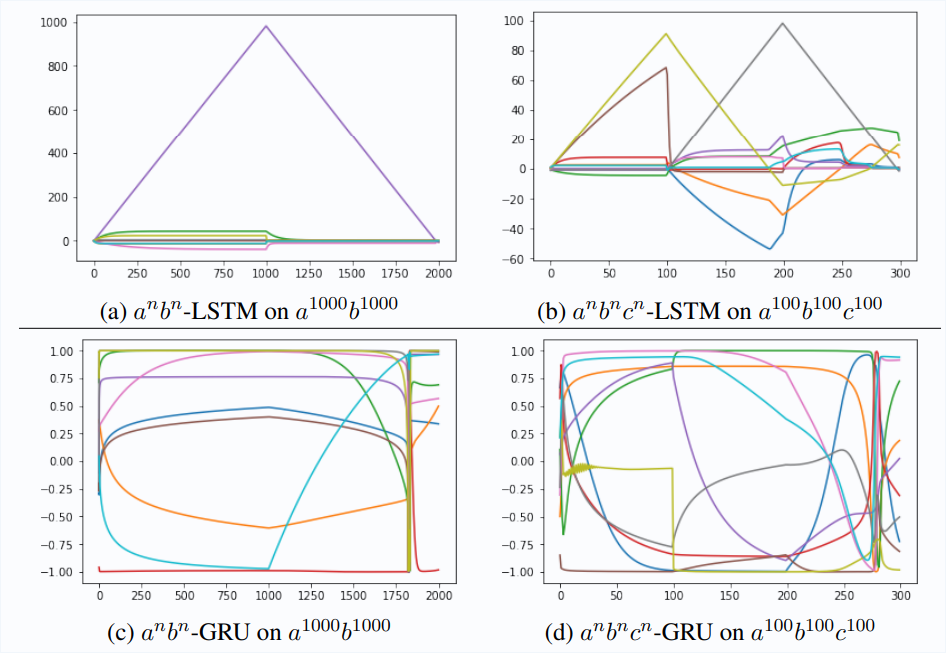
On the Practical Computational Power of Finite Precision RNNs for Language Recognition (2018)
Application: Machine Translation
![]()
Application: Handwriting from Text
Input: "He dismissed the idea"
Output:
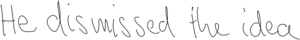
Application: Handwriting from Text
Input: "He dismissed the idea"
Output:
Generating Sequences With Recurrent Neural Networks, Alex Graves, 2013
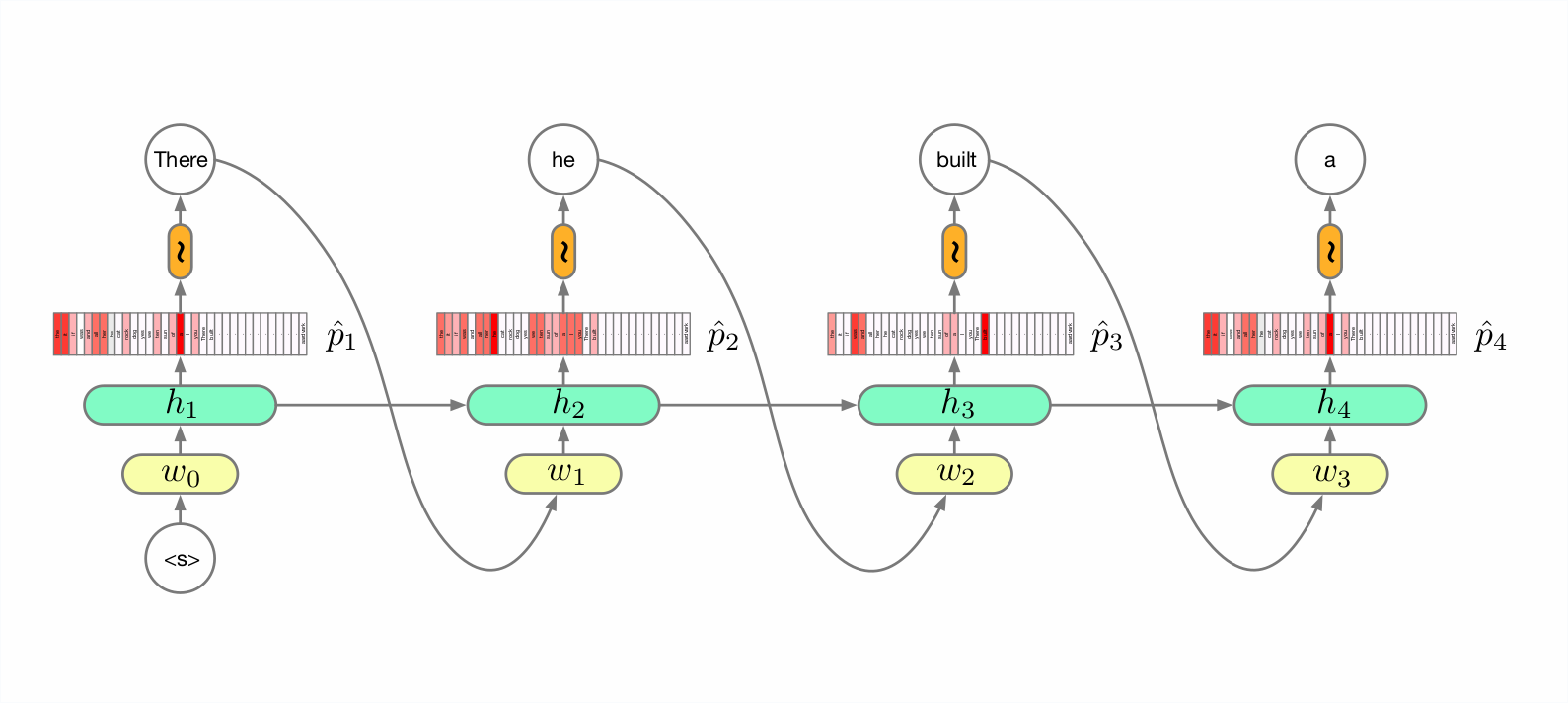
Application: Character-Level Text Generation
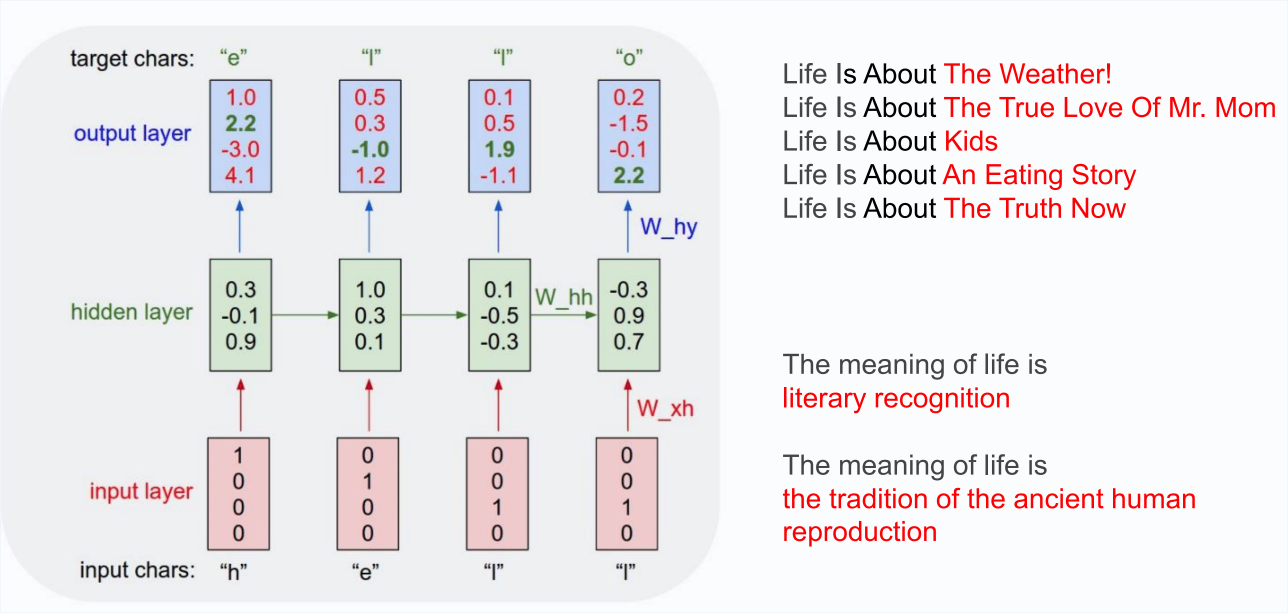
"The Unreasonable Effectiveness of Recurrent Neural Networks", Andrej Karpathy, 2015
Application: Image Question Answering

Application: Image Question Answering
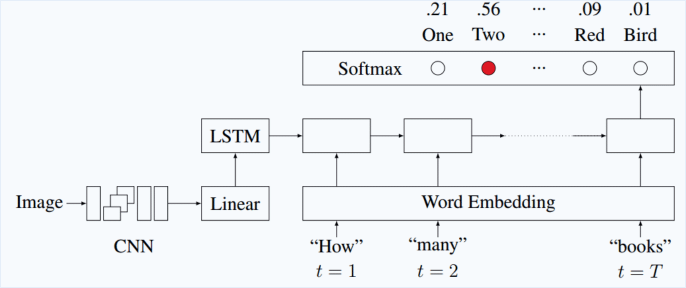 Exploring Models and Data for Image Question Answering, 2015
Exploring Models and Data for Image Question Answering, 2015
Live Demo at https://vqa.cloudcv.org/
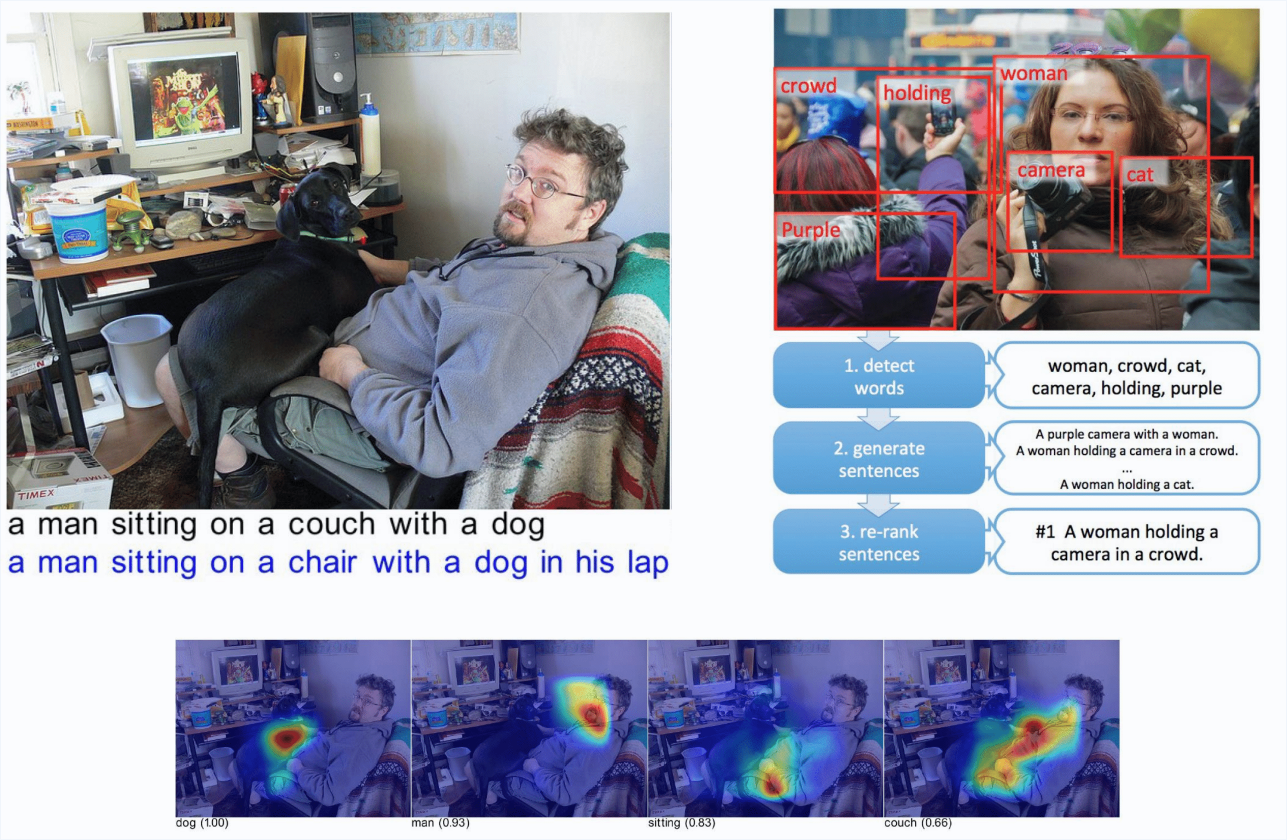
Application: Image Caption Generation
Application: Video Caption Generation

Application: Video Caption Generation
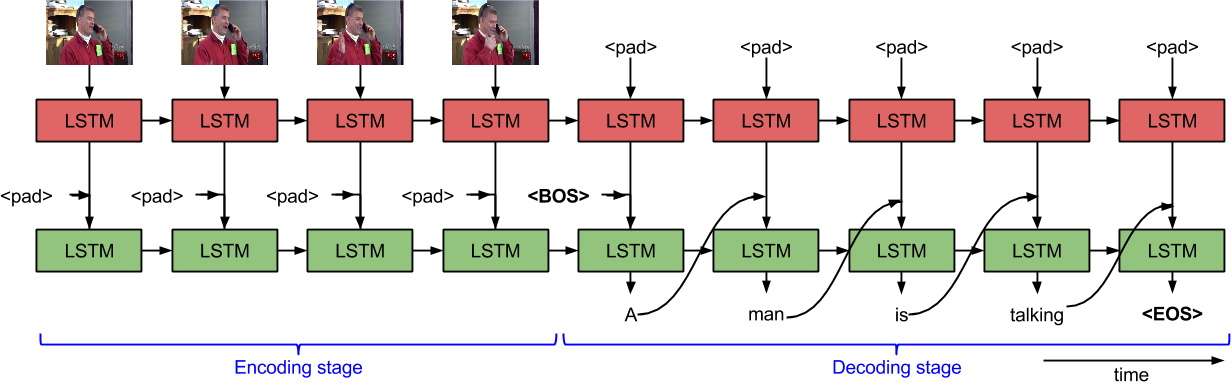 Sequence to Sequence - Video to Text, Venugopalan et al., 2015
Sequence to Sequence - Video to Text, Venugopalan et al., 2015
Application: Adding Audion to Silent Film
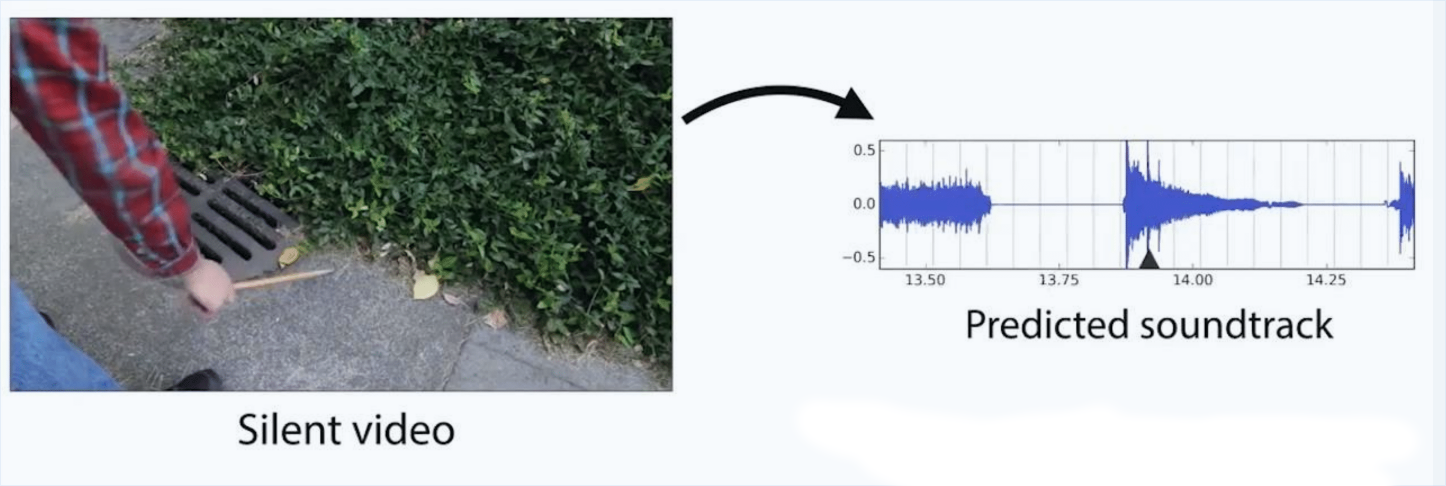
Application: Adding Audion to Silent Film
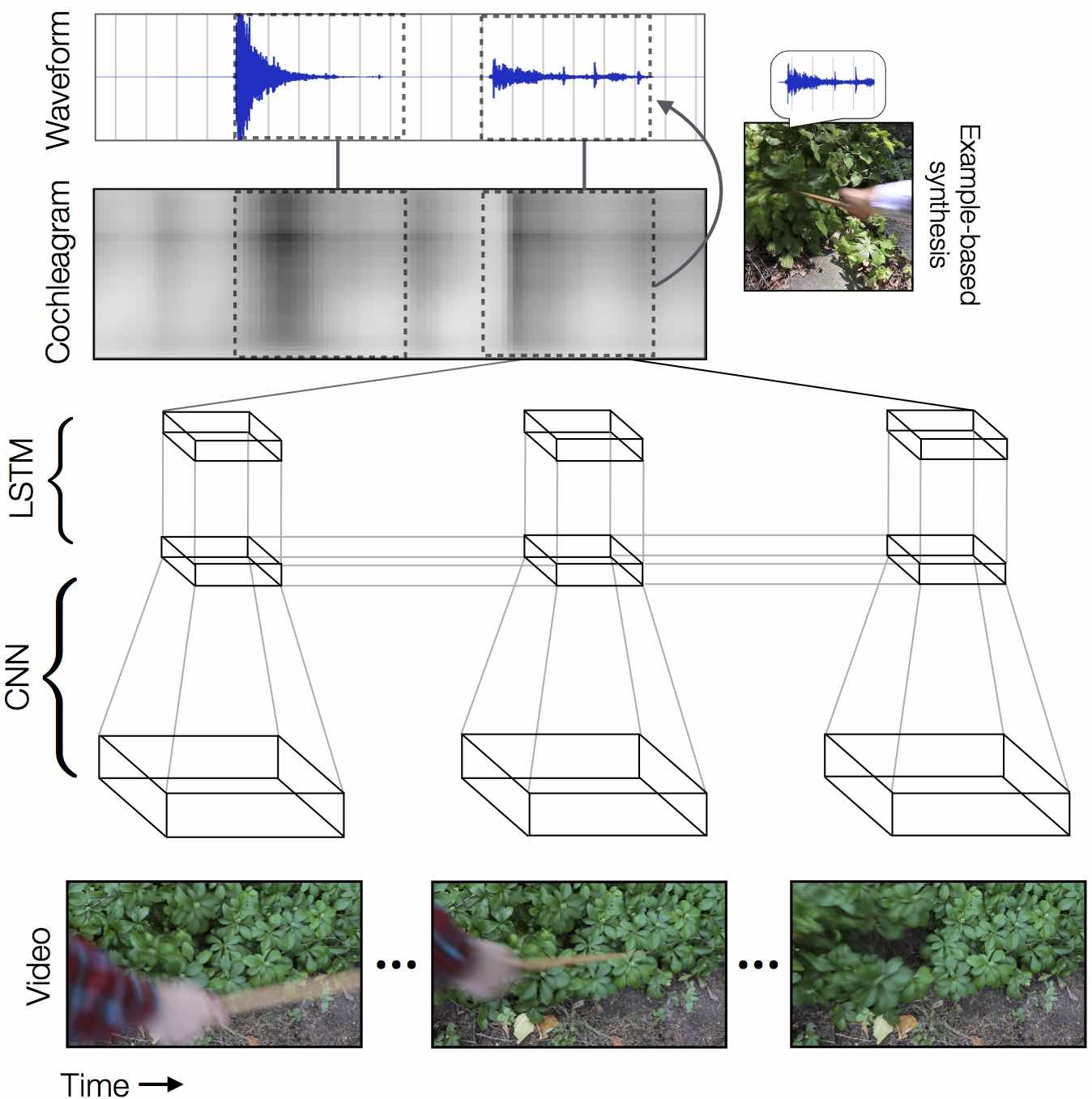 Visually Indicated Sounds, Owens et al., 2015
Visually Indicated Sounds, Owens et al., 2015
More at http://andrewowens.com/vis/
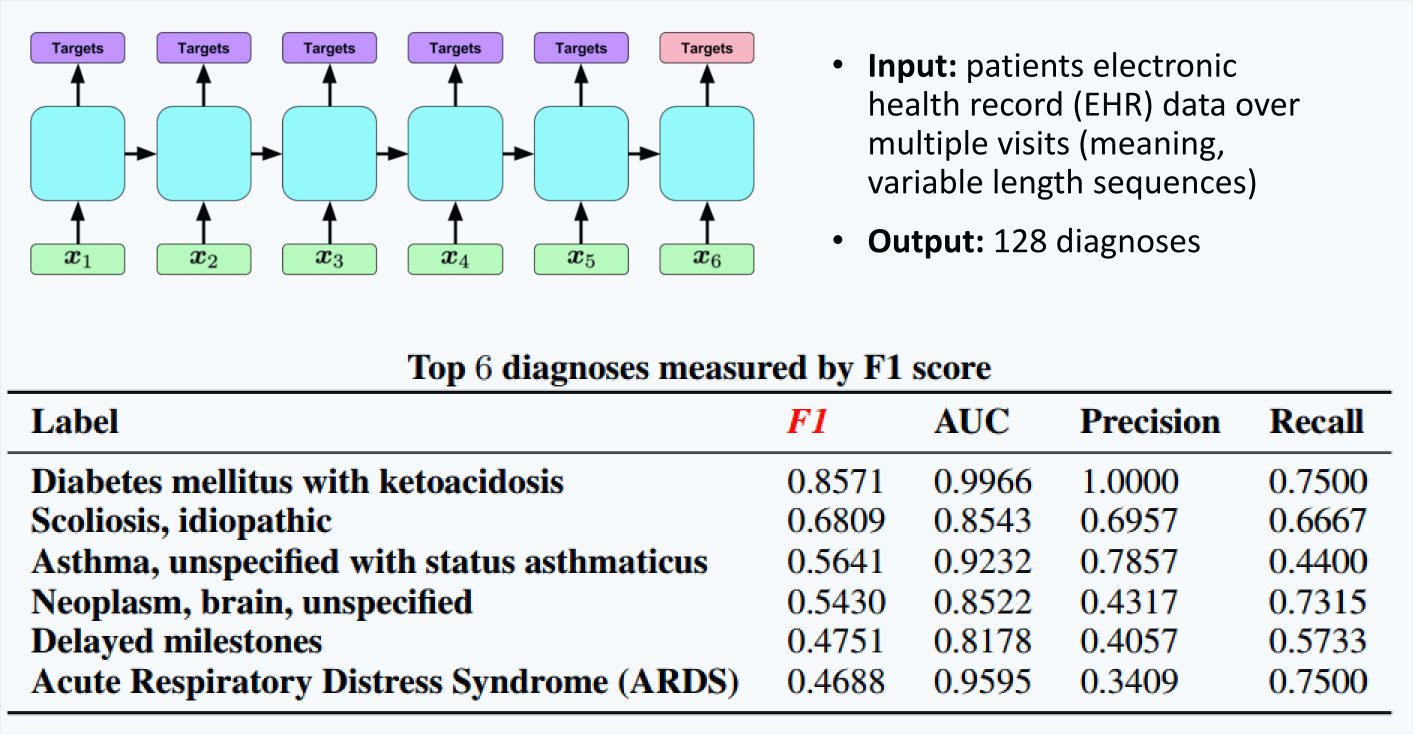
Application: Medical Diagnosis
Application: End-to-End Driving *

Application: End-to-End Driving *
Input: features extracted from CNN Output: predicted steering angle
* On relatively straight roads
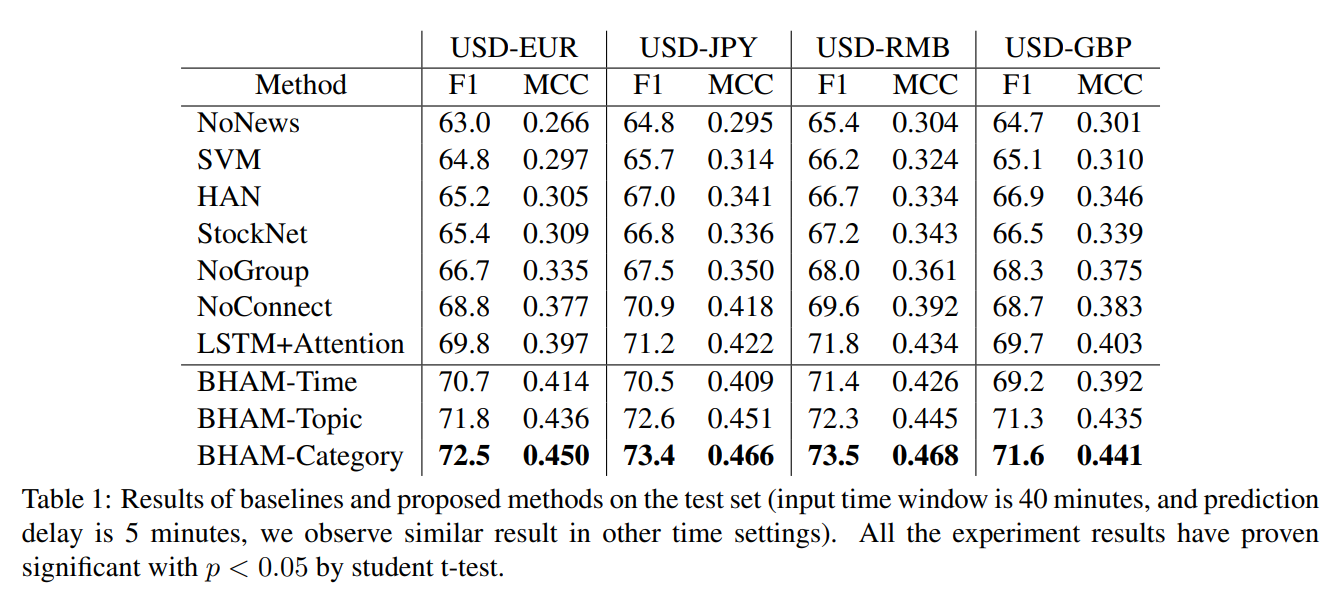
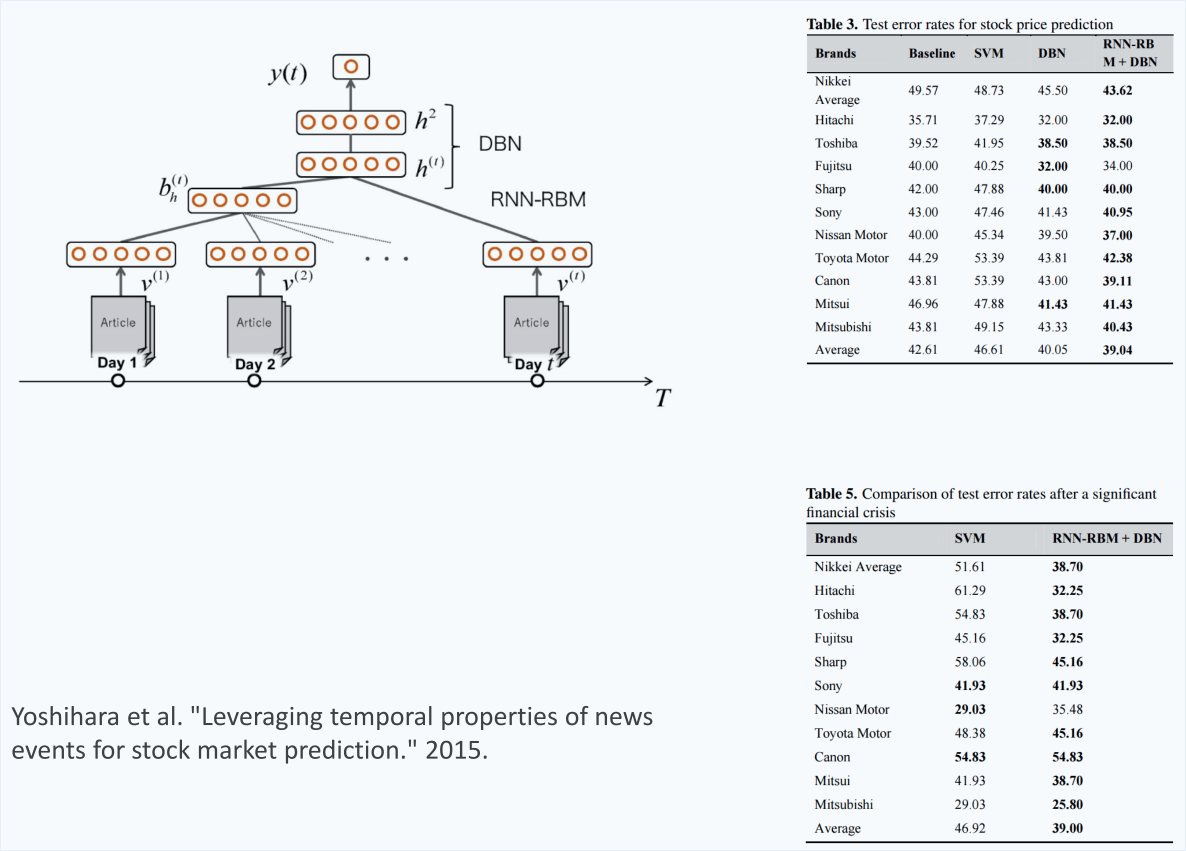
Application: Stock Market Prediction
Application: Named Entity Recognition (NER)
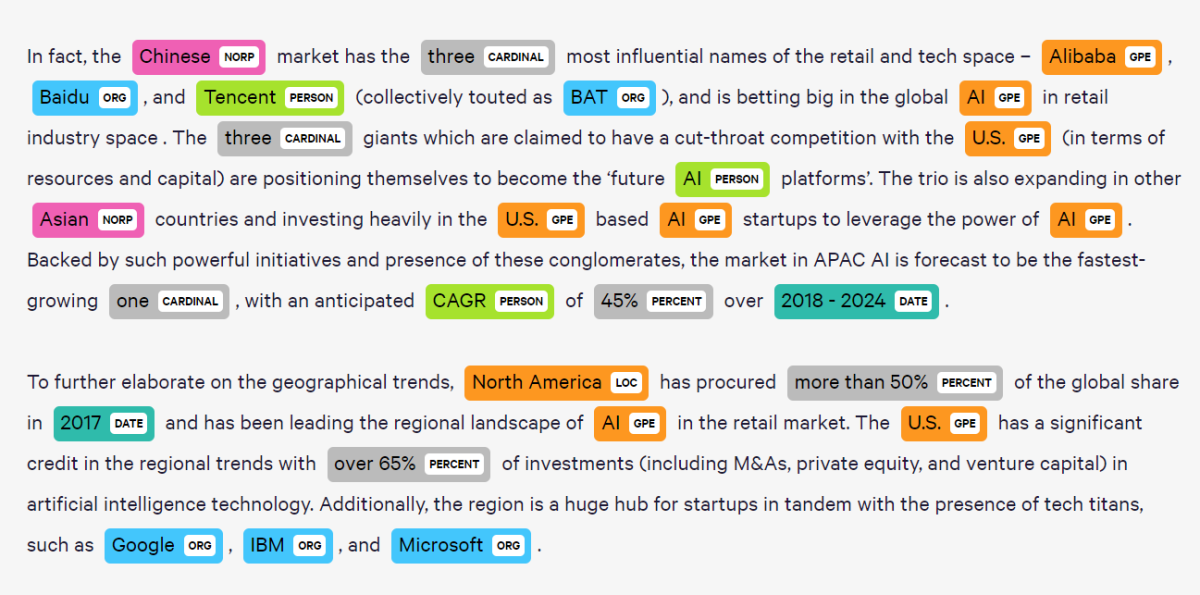
Try it yourself at https://demo.allennlp.org/named-entity-recognition/
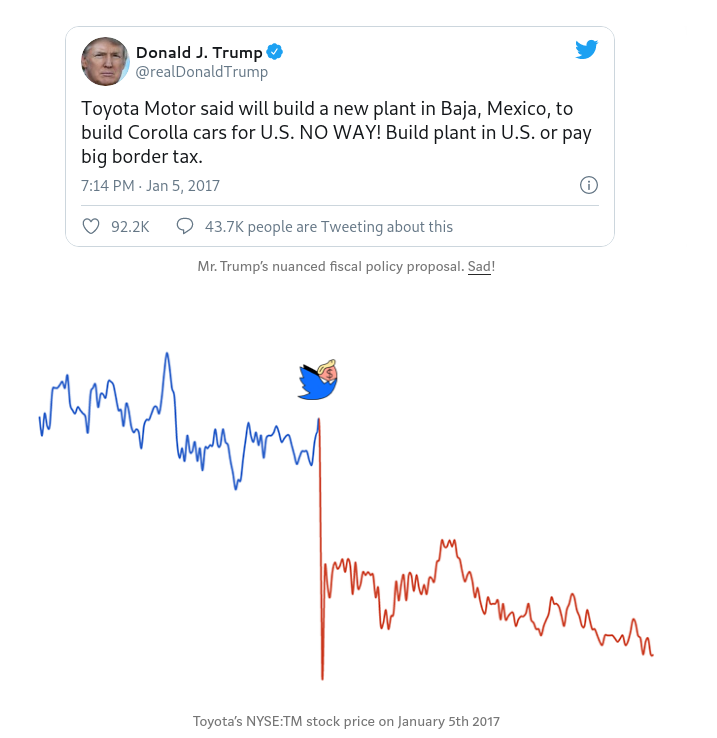
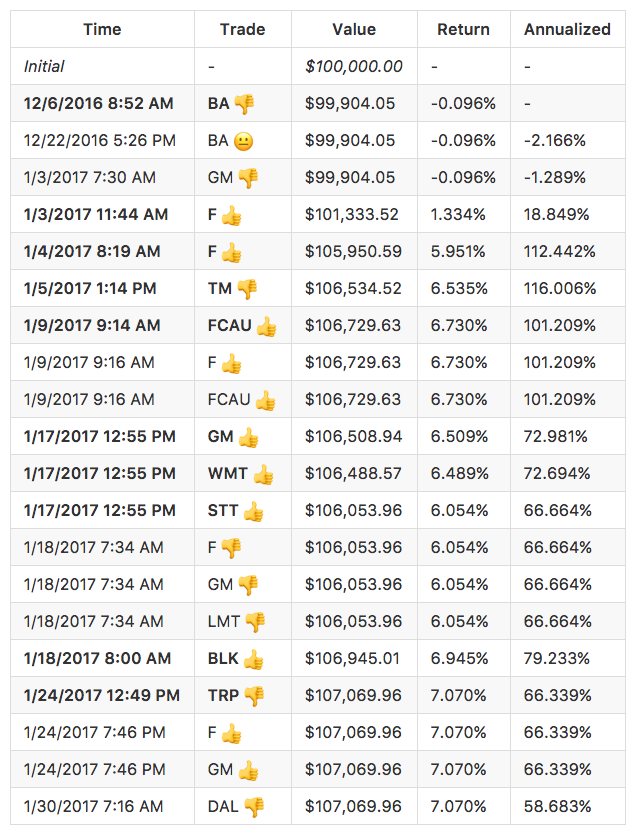
Application: Trump2Cash
History of Deep Learning Milestones

From Deep Learning State of the Art (2020) by Lex Fridman at MIT

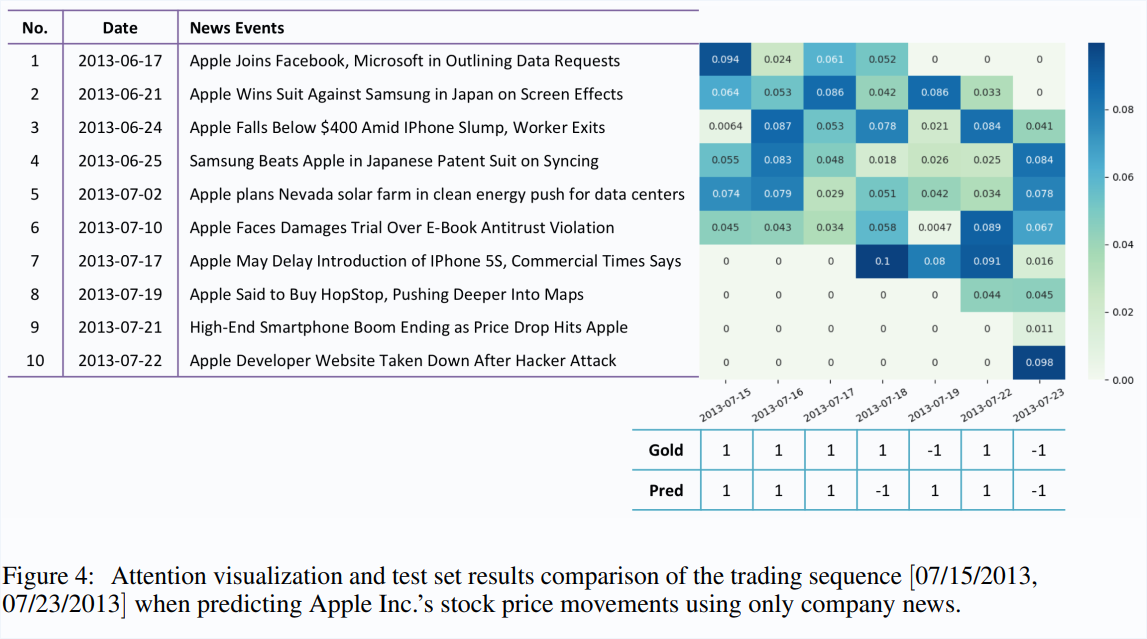
Attention also helps explainability of stock prediction
The Transformer's Encoder
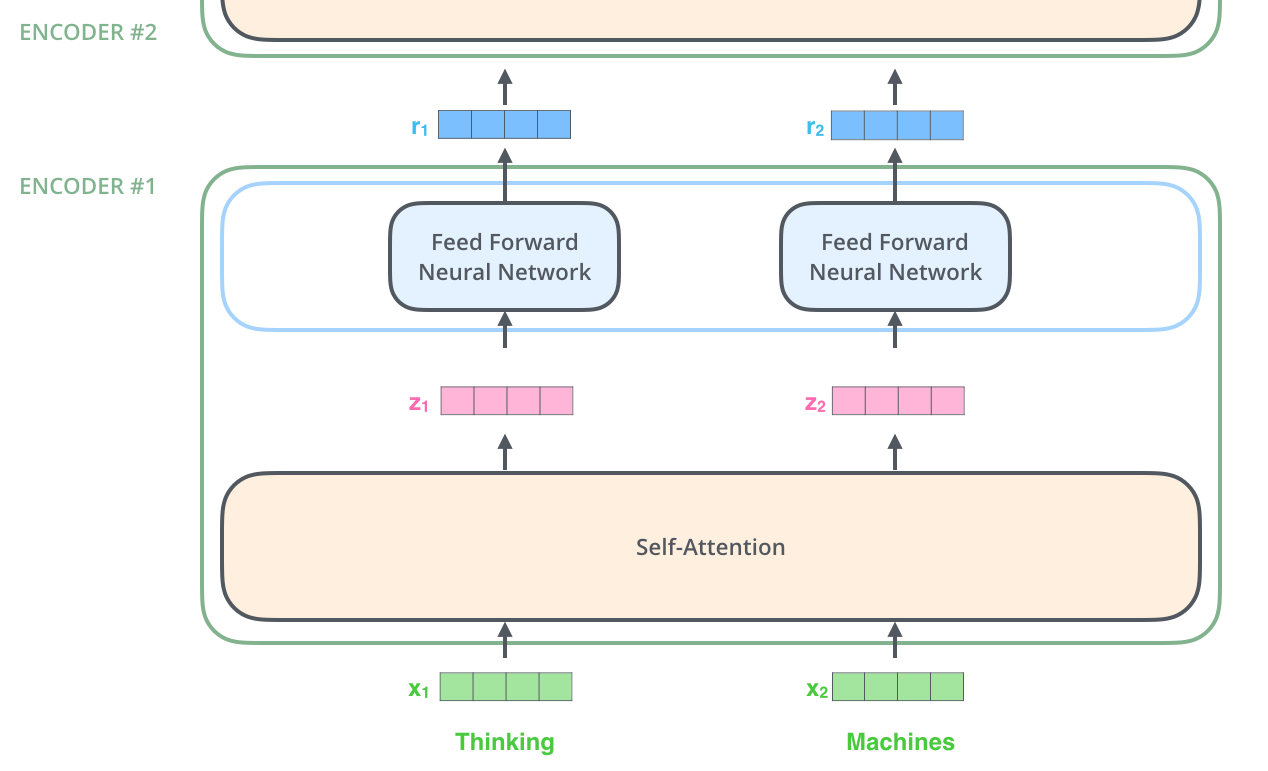
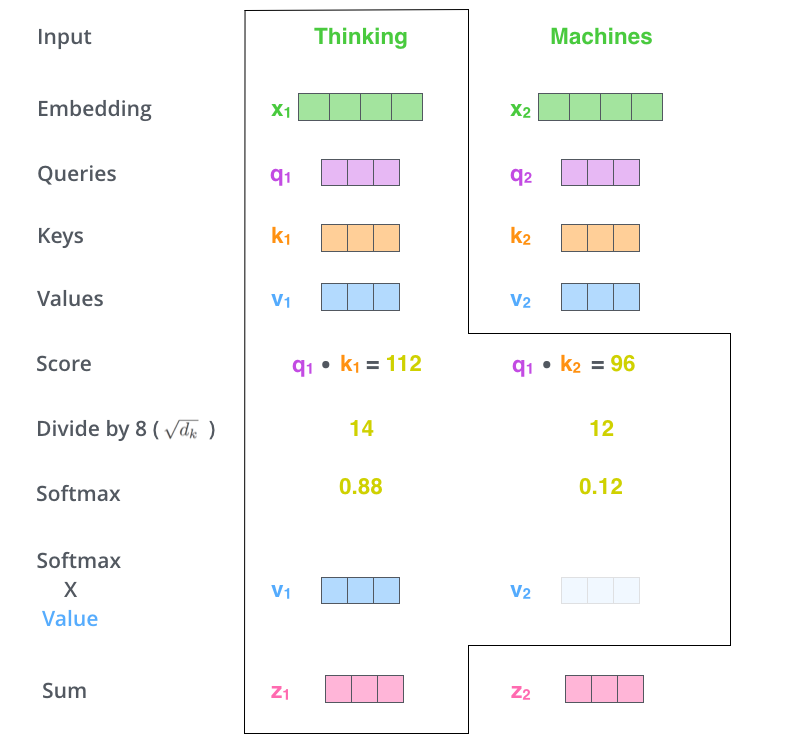
What's Self Attention?
The animal didn't cross the street because it was too tired.
What does "it" refer to?
![]()
Self Attention mechanics
The full Transformer seq2seq process
![]()

Big Transformers Wins: BERT
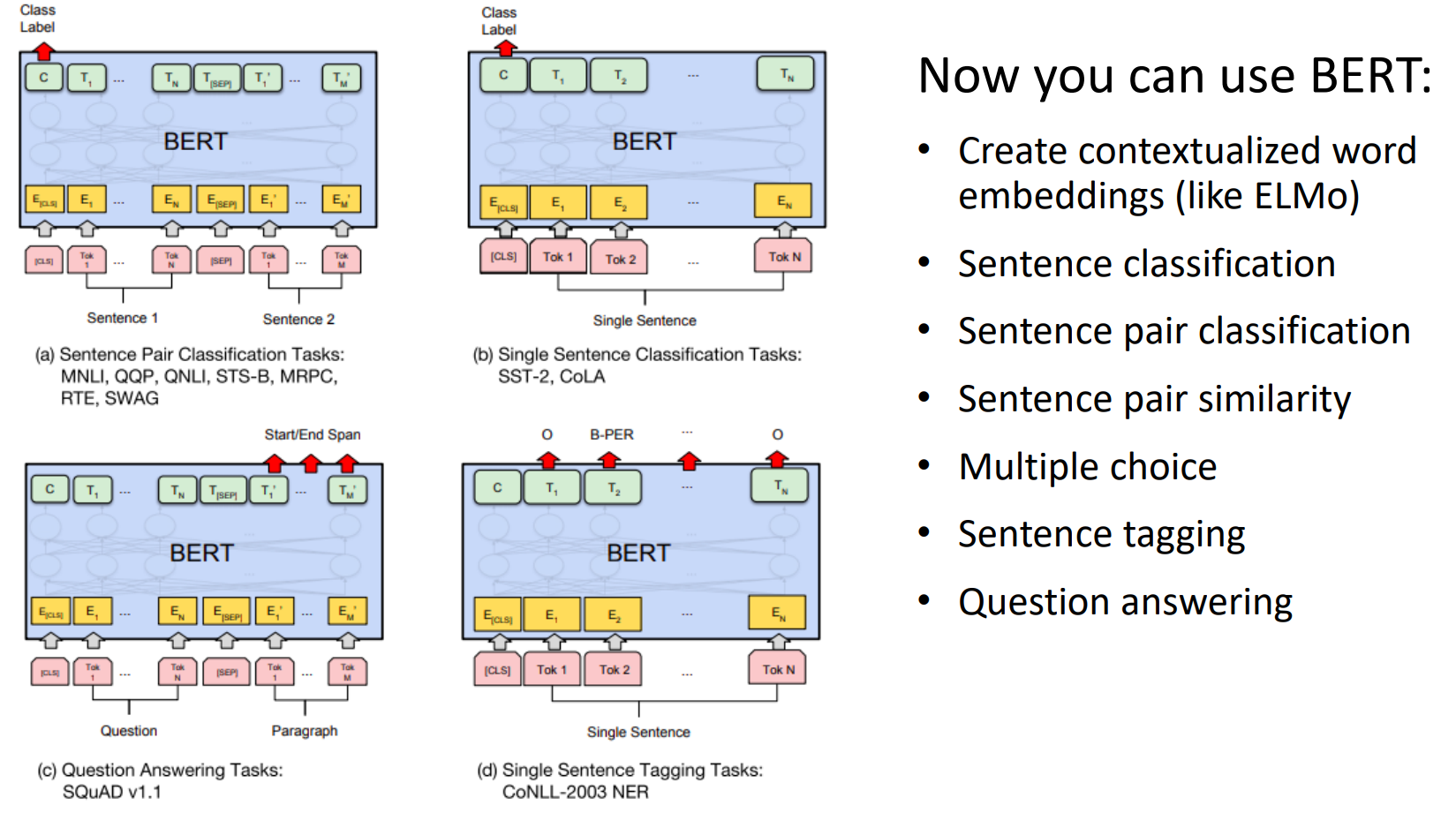
BERT: for Forex Movement Prediction
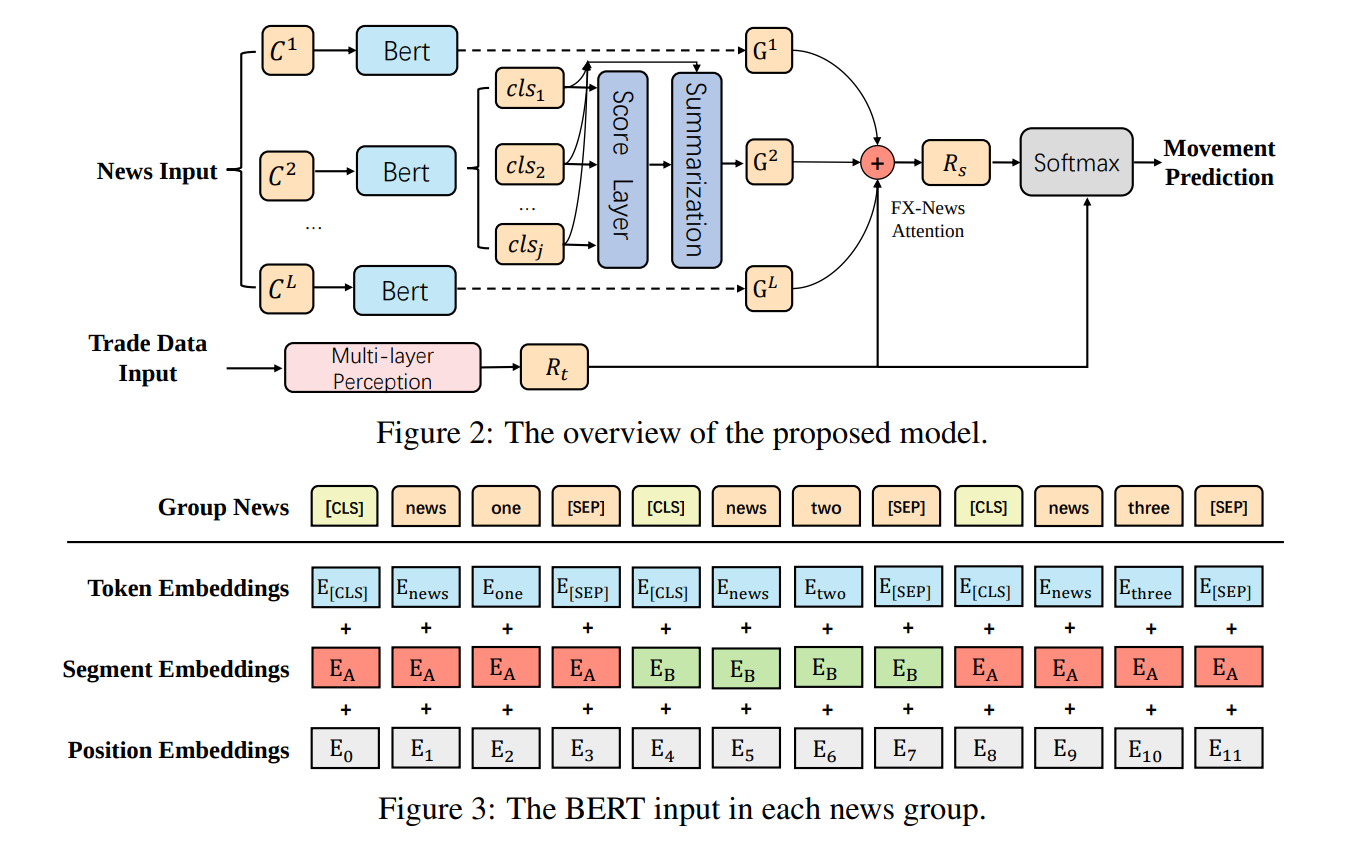
BERT: for Forex Movement Prediction